EKS · Central VPC 인프라
EKS 기반 애플리케이션 플랫폼과 Central VPC 중앙 관제 네트워크를 설계·구축했습니다. QA 환경에서 2,000 RPS · 12만 요청을 처리하며 구조의 유효성을 검증했습니다.
담당 역할: 팀장으로서 전체 일정과 방향을 조율했고, 기술적으로는 쿠버네티스 중심 아키텍처 설계와 EKS 학습·구축을 주도했습니다. 일부 모니터링 및 알림 체계 구성에도 참여했습니다.
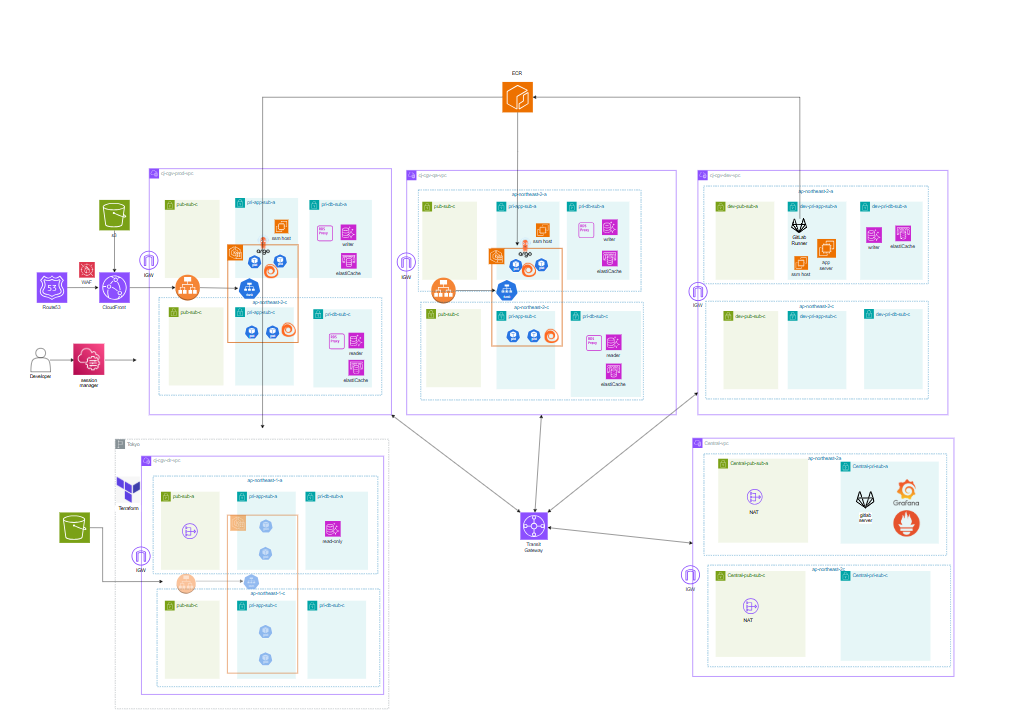
전체 구조는 Prod / QA / Dev / DR / Central VPC로 나뉩니다. Prod와 QA는 공통적으로 CloudFront → ALB(Ingress) → Kubernetes Service → Pod 흐름의 EKS 기반 구조를 사용했고, 가용성을 위해 멀티 AZ로 구성했습니다. 데이터 계층은 Aurora DB + Reader Endpoint + RDS Proxy로 설계해 읽기 트래픽 분산과 커넥션 안정성을 확보했습니다. Prod는 On-Demand + Spot NodePool 분리 운영, QA는 비용 절감을 위해 Spot 중심으로 운영했습니다. Central VPC에는 GitLab 서버와 모니터링 스택 서버를 두어 여러 환경을 한 곳에서 관리하는 중앙 관제형 구조를 만들었고, DR은 Pilot Light 방식으로 설계해 평시 비용을 줄이고 필요 시 복구 가능한 형태로 구성했습니다. DNS 질의 흐름은 Route 53 Resolver → DNS Firewall(ALERT) → Query Logging → CloudWatch Logs → Metric Filter → Alarm → SNS → Lambda → Slack Alert로 연결해 외부 도메인 접근을 추적할 수 있도록 구성했습니다.
설계 근거
EKS를 선택한 이유는 단순 배포 편의성보다 확장성과 생태계 활용성 때문이었습니다. KEDA·Karpenter·IRSA 등 오픈소스와의 연계성이 뛰어났고, Helm Chart로 배포와 운영 구성을 일관되게 관리할 수 있었습니다. Central VPC는 공통 서비스를 중앙화해 운영 복잡도를 낮추고, 여러 VPC의 상태·로그·알람을 한 곳에서 모아 가시성과 장애 대응 속도를 높이는 구조로 설계했습니다. 즉 '네트워크를 나눈 설계'가 아니라 운영·보안·관측 포인트를 줄인 설계입니다.
인프라를 코드로 관리해 수동 구성 오류를 줄이고, DR에서도 Pilot Light 구조를 재현 가능한 형태로 가져가기 위해 선택했습니다.
트래픽 변동 대응, 오토스케일링, 모니터링, GitOps, 오픈소스 연동 등 운영 요구사항이 많은 구조에 적합했고, KEDA·Karpenter·IRSA 등과의 연계성이 뛰어났기 때문입니다.
CPU/메모리 기준보다 실제 요청량 기준 확장이 더 적합하다고 판단해, Prometheus 메트릭을 기반으로 Pod당 평균 RPS를 계산해 확장하도록 설계했습니다. 최소 45개, 최대 110개까지 확장 가능하게 구성했습니다.
Pod 수만 늘려서는 충분하지 않고, 실제 스케줄링 가능한 노드가 함께 늘어나야 했기 때문에 사용했습니다. Pending Pod 감지 후 필요한 노드를 자동으로 생성하는 구조를 설계했습니다.
Git 기준으로 배포 상태를 일관되게 유지하고, 운영 변경 이력을 명확하게 관리하기 위해 도입했습니다.
앱 배포, 모니터링 스택, 오토스케일링 관련 설정을 일관되게 관리하기 위해 사용했습니다.
/actuator/prometheus 메트릭을 수집해 KEDA가 요청량 기반으로 스케일링 결정을 내릴 수 있게 만들기 위해 사용했습니다.
노드 전체 IAM Role에 권한을 몰아주지 않고, ServiceAccount 단위로 필요한 권한만 부여해 보안 범위를 최소화하기 위해 적용했습니다.
Central VPC 내부 서버의 외부 도메인 접근을 추적하고, 위험 도메인 탐지 이벤트를 Slack으로 빠르게 전달하기 위해 구성했습니다.
- 이슈
- 대규모 부하 상황에서 준비되지 않은 Pod에 트래픽이 들어갈 위험, 요청량에 비해 느린 확장, Pod는 늘어나지만 노드가 부족해 Pending이 발생할 위험이 함께 존재했습니다. 실제로 노드 Join 실패, Pending Pod, MaxPods 한계, ALB 헬스체크 경로 불일치 같은 문제가 반복적으로 나타났습니다.
- 분석
- 문제를 레이어별로 분리해 분석했습니다. Spring Boot는 부팅 직후 바로 요청을 받으면 안 되기 때문에 readiness 기준이 중요했고, HPA만으로는 실제 요청량을 충분히 반영하기 어려웠습니다. 또한 Private Subnet 라우팅 오류로 워커 노드가 EKS API와 통신하지 못해 Join에 실패했고, DNS 설정 오류로 Node가 NotReady가 되었으며, MaxPods 한계로 Pending Pod가 발생하는 문제를 확인했습니다.
- 해결
- 단일 기술이 아닌 여러 계층을 맞물리게 설계했습니다. startup/readiness/liveness probe를 분리하고 ALB health check 경로를 readiness와 동일하게 맞췄습니다. CPU 기준 대신 Prometheus 메트릭 기반 KEDA로 Pod당 평균 RPS를 기준으로 스케일링하도록 했고, 최소 45개 Pod를 선기동해 초기 수용량을 확보했습니다. Karpenter를 함께 적용해 Pending Pod 발생 시 새 노드가 자동으로 추가되도록 했으며, IRSA로 Pod 단위 권한을 분리했습니다.
- 결과
- QA 환경에서 약 2,000 RPS를 60초 동안 유지하며 총 120,000 요청을 처리했습니다. 초기 45개 Pod 확보, readiness/ALB health check 기준 통일, Prometheus 기반 KEDA 확장, Karpenter 기반 노드 확장, GitOps 기반 운영 일관성이 함께 작동한 결과였습니다.
⚙ 개선점
EKS 기반 대규모 트래픽 대응 구조를 실제 요청으로 검증했습니다. Central VPC를 통해 GitLab·모니터링·보안 관측을 중앙화해 운영 복잡도를 낮추고 가시성을 높였으며, DNS Firewall + Query Logging + Slack Alert를 통해 네트워크 보안 이벤트를 탐지하고 즉시 인지할 수 있는 흐름을 만들었습니다.
△ 아쉬운 점
부하 테스트 과정에서 리소스 스펙을 충분히 정교하게 잡지 못해 예산을 초과했습니다. 또한 Karpenter를 완전한 GitOps 흐름 안에 넣지 못했고, DNS Firewall도 ALERT 모드 위주로만 사용해 차단 정책까지는 확장하지 못했습니다.
→ 향후 방향
Karpenter까지 포함한 완전한 GitOps화, Central VPC 보안 정책의 BLOCK/탐지 규칙 고도화, 부하 테스트 기반 비용 예측 정교화를 다음 단계로 진행할 계획입니다.